It is common to have a remote and dispersed team these days. As face to face meetings are less common and with geographically dispersed development teams not possible, it is challenging to have a clear picture of where your team is.
GitHub provides useful data to help us understand your development team's workload and progress. StackQL has an official GitHub provider which allows you to access this data using SQL.
StackQL is an open source project which enables you to query, analyze and interact with cloud and SaaS provider resources using SQL, see stackql.io
In this example we will use the pystackql Python package (Python wrapper for StackQL) along with a Jupyter Notebook to retrieve data from GitHub using SQL, then sink the data into a cloud native data warehouse for long term storage and analytics at scale, in this example we have used BigQuery.
This guide will walk you through the steps involved in capturing and analyzing developer data using StackQL, Python, Jupyter and BigQuery.
You will need to create a Personal Access Token in GitHub for a user which has access to the org or orgs in GitHub you will be analyzing. Follow this guide to create your GitHub token and store it somewhere safe.
You need to set up your Jupyter environment, you can either use the Docker, see stackql/stackql-jupyter-demo or:
- Create your Jupyter project
- Download and install StackQL
- Clone the pystackql repo
You can find instructions on how to use your personal access token to authenticate to GitHub here. The following example shows how to do this in a Jupyter notebook cell using pystackql.
Next, we will use StackQL SQL queries to get commits, pull requests and pull request reviews, then we will aggregate by usernames of contributors. You can use JOIN semantics in StackQL to do this as well.
In the following cell we will query data from GitHub using StackQL:
Now we will aggregate the data by each contributor, see the following example:
After the transformation of data, we will then upload it to BigQuery. First, we will store the data as a new line delimited json file, making the uploading process much easier and handling the nested schema better, as shown in the following cell:
Now we can see the table on BigQuery as shown here:
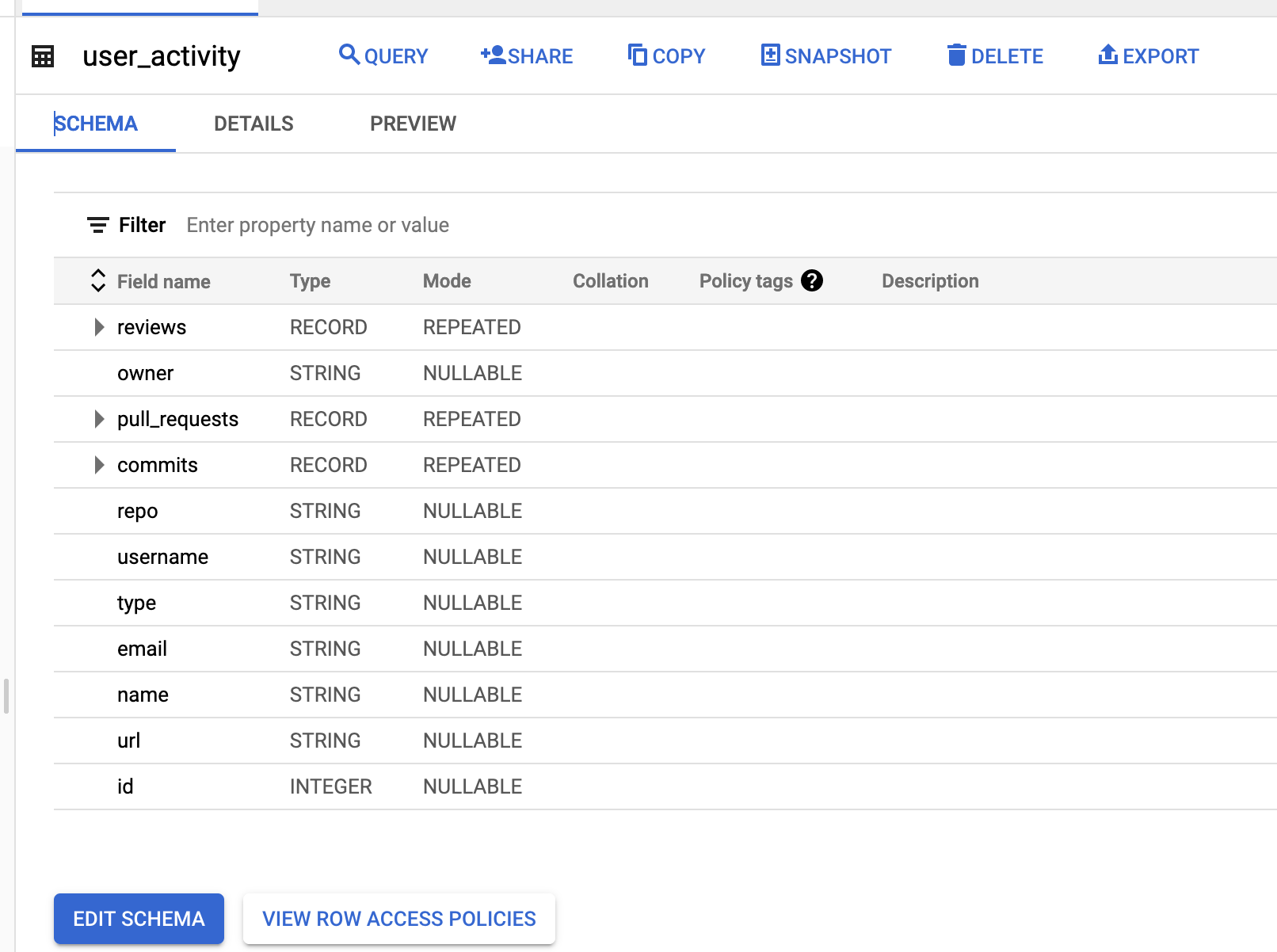
From here you can use the same process to append data to the table and use BigQuery to perform analytics at scale on the data.


