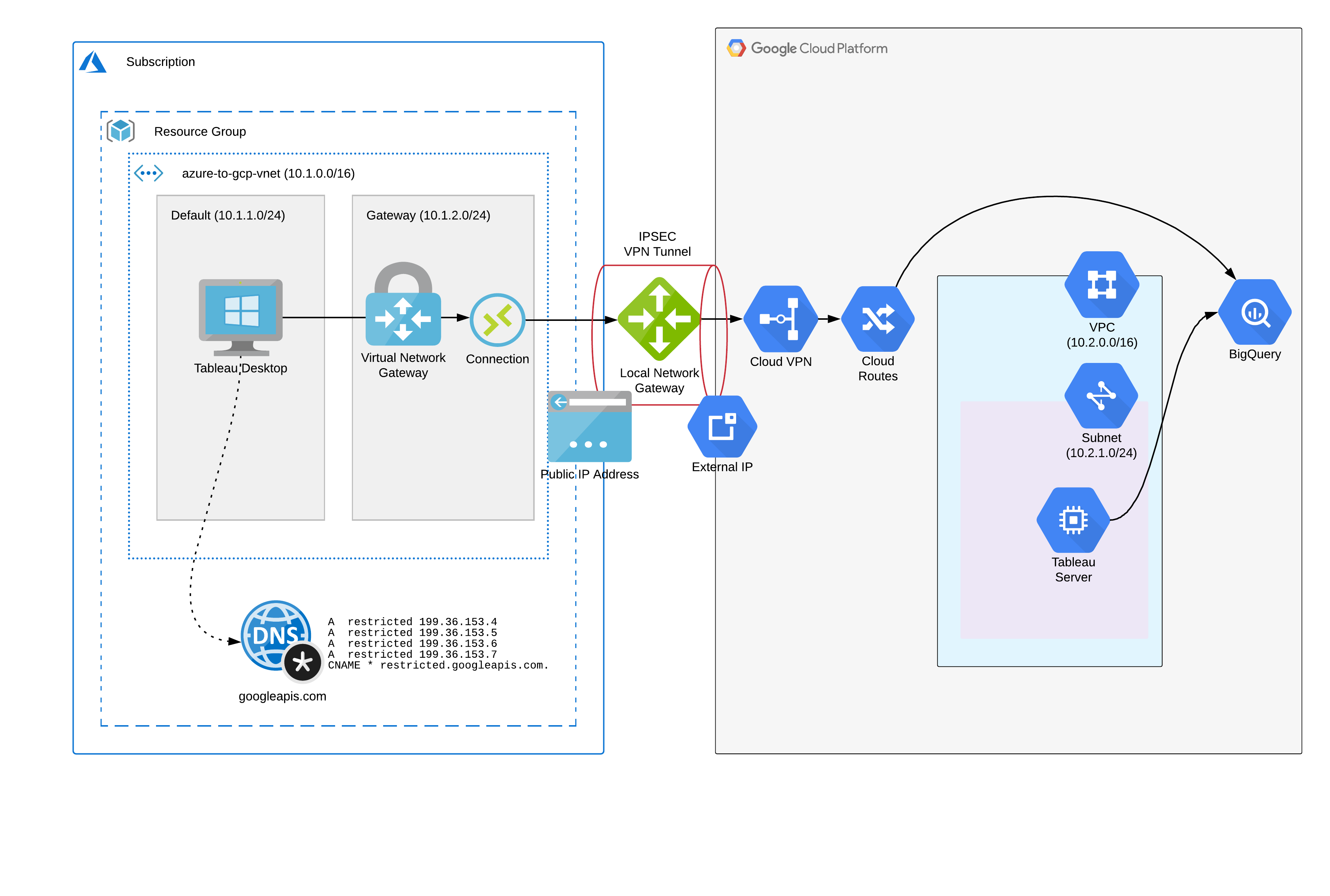
Terraform is a powerful tool for managing your Infrastructure as Code. Declare your resources once, define their variables per environment and sleep easy knowing your CI pipeline will take care of the rest.
But… one night you wake up in a sweat. The details are fuzzy but you were browsing your favourite cloud provider’s console - probably GCP ;) - and thought you saw a bucket had been created outside of your allowed locations! Maybe it even had risky access controls.
You go brush it off and try to fall back to sleep, but you can’t quite push the thought from your mind that somewhere in all that Terraform code, someone could be declaring resources in unapproved locations, and your CICD pipeline would do nothing to stop it. Oh the regulatory implications.
Enter Terraform Validator by Forseti
Terraform Validator by Forseti allows you to declare your Policy as Code, check compliance of your Terraform plans against said Policy, and automatically fail violating plans in a CI step. All without setting up servers or agents.
You’re going to learn how to enforce policy on GCP resources like BigQuery, IAM, networks, MySQL, Google Kubernetes Engine (GKE) and more. If you’re particularly crafty, you may be able to go beyond GCP.
Forseti’s suite of solutions are GCP focused and allow a wide range of live config validation, monitoring and more using the Policy Library we’re going to set up. These additional capabilities require additional infrastructure. But we’re going one step at a time, starting with enforcing policy during deployment.
Getting Started
Let’s assume you already have an established CICD pipeline that uses Terraform, or that you are content to validate your Terraform plans locally for now. In that case, we need just two things:
- A Policy Library
- Terraform Validator
It’s that simple! No new servers, agents, firewall rules, extra service accounts or other nonsense. Just add Policy Library, the Validator tool and you can enforce policy on your Terraform deployments.
We’re going to tinker with some existing GCP-focused sample policies (aka Constraints) that Forseti makes available. These samples cover a wide range of resources and use cases, so it is easy to adjust what’s provided to define your own Constraints.
Policy Library
First let's open up some of Forseti's pre-defined constraints. We’ll copy them into our own Git repository and adjust to create policies that match our needs. Repeatable and configurable - that’s Policy as Code at work.
Concepts
In the world of Forseti and in particular Terraform Validator, Policies are defined and understood via easy to read YAML files known as Constraints
There is just enough information in a Constraint file for to make clear its purpose and effect, and by tinkering lightly with a pre-written Constraint you can achieve a lot without looking too deeply into the inner workings . But there’s more happening than meets the eye.
Constraints are built on Templates - which are like forms with some extra bits waiting to be completed to make a Constraint. Except there’s a lot more hidden away that’s pretty cool if you want to understand it.
Think of a Template as a ‘Class’ in the OOP sense, and of a Constraint as an instantiated Template with all the key attributes defined.
E.g. A generic Template for policy on bucket locations and a Constraint to specify which locations are relevant in a given instance. Again, buckets and locations are just the basic example - the potential applications are far greater.
Now the real magic is that just like a ‘Class’, a Template contains logic that makes everything abstracted away in the Constraint possible. Templates contain inline Rego (ray-go), borrowed lovingly by Forseti from the Open Policy Agent (OPA) team.
Learn more about Rego and OPA here to understand the relationship to our Terraform Validator.
But let’s begin.
Set up your Policies
Create your Policy Library repository
Create your Policy Library repository by cloning https://github.com/forseti-security/policy-library into your own VCS.
This repo contains templates and sample constraints which will form the basis of your policies. So get it into your Git environment and clone it to local for the next step.
Customise sample constraints to fit your needs
As discussed in Concepts, Constraints are defined Templates, which make use of Rego policy language. Nice. So let’s take a sample Constraint, put it in our Policy Library and set the values to what we need. It’s that easy - no need to write new templates or learn Rego if your use case is covered.
In a new branch…
- Copy the sample Constraint
storage_location.yamlto your Constraints folder.
$ cp policy-library/samples/storage_location.yaml policy-library/policies/constraints/storage_location.yaml
- Replace the sample location (
asia-southeast1) instorage_location.yamlwithaustralia-southeast1.
spec:
severity: high
match:
target: ["organization/*"]
parameters:
mode: "allowlist"
locations:
- australia-southeast1
exemptions: []
- Push back to your repo - not Forseti’s!
$ git push https://github.com/<your-repository>/policy-library.git
Policy review
There you go - you’ve customised a sample Constraint. Now you have your own instance of version controlled Policy-as-Code and are ready to apply the power of OPA’s Rego policy language that lies within the parent Template. Impressively easy right?
That’s a pretty simple example. You can browse the rest of Forseti’s Policy Library to view other sample Constraints, Templates and the Rego logic that makes all of this work. These can be adjusted to cover all kinds of use cases across GCP resources.
I suggest working with and editing the sample Constraints before making any changes to Templates.
If you were to write Rego and Templates from scratch, you might even be able to enforce Policy as Code against non-GCP Terraform code.
Terraform Validator
Now, let’s set up the Terraform Validator tool and have it compare a sample piece of Terraform code against the Constraint we configured above. Keep in mind you’ll want to translate what’s done here into steps in your CICD pipeline.
Once the tool is in place, we really just run terraform plan and feed the output into Terraform Validator. The Validator compares it to our Constraints, runs all the abstracted logic we don’t need to worry about and returns 0 or 2 when done for pass / fail respectively. Easy.
So using Terraform if I try to make a bucket in australia-southeast1 it should pass, if I try to make one in the US it should fail. Let’s set up the tool, write some basic Terraform and see how we go.
Setup Terraform Validator
Check for the latest version of terraform-validator from the official terraform-validator GCS bucket.
Very important when using tf version 0.12 or greater. This is the easy way - you can pull from the Terraform Validator Github and make it yourself too.
$ gsutil ls -r gs://terraform-validator/releases
Copy the latest version to the working dir
$ gsutil cp gs://terraform-validator/releases/2020-03-05/terraform-validator-linux-amd64 .
Make it executable
$ chmod 755 terraform-validator-linux-amd64
Ready to go!
Review your Terraform code
We’re going to make a ridiculously simple piece of Terraform that tries to create one bucket in our project to keep things simple.
# main.tf
resource "google_storage_bucket" "tf-validator-demo-bucket" {
name = "tf-validator-demo-bucket"
location = "US"
force_destroy = true
lifecycle_rule {
condition {
age = "3"
}
action {
type = "Delete"
}
}
}
This is a pretty standard bit of Terraform for a GCS bucket, but made very simple with all the values defined directly in main.tf. Note the location of the bucket - it violates our Constraint that was set to the australia-southeast1 region.
Make the Terraform plan
Warm up Terraform.
Double check your Terraform code if there are any hiccups.
$ terraform init
Make the Terraform plan and store output to file.
$ terraform plan --out=terraform.tfplan
Convert the plan to JSON
$ terraform show -json ./terraform.tfplan > ./terraform.tfplan.json
Validate the non-compliant Terraform plan against your Constraints, for example
$ ./terraform-validator-linux-amd64 validate ./tfplan.tfplan.json --policy-path=../repos/policy-library/
TA-DA!
Found Violations:
Constraint allow_some_storage_location on resource //storage.googleapis.com/tf-validator-demo-bucket: //storage.googleapis.com/tf-validator-demo-bucket is in a disallowed location.
Validate the compliant Terraform plan against your Constraints
Let’s see what happens if we repeat the above, changing the location of our GCS bucket to australia-southeast1.
$ ./terraform-validator-linux-amd64 validate ./tfplan.tfplan.json --policy-path=../repos/policy-library/
Results in..
No violations found.
Success!!!
Now all that’s left to do for your Policy as Code CICD pipeline is to configure the rest of your Constraints and run this check before you go ahead and terraform apply. Be sure to make the apply step dependent on the outcome of the Validator.
Wrap Up
We’ve looked at how to apply Policy as Code to validate our Infrastructure as Code. Sounds pretty modern and DevOpsy doesn’t it.
To recap, we learned about Constraints, which are fully defined instances of Policy as Code. They’re based on YAML Templates that refer to the OPA policy language Rego, but we didn’t have to learn it :)
We created our own version controlled Policy Library.
Using the above learning and some handy pre-existing samples, we wrote policies (Constraints) for GCP infrastructure, specifying a whitelist for locations in which GCS buckets could be deployed.
As mentioned there are dozens upon dozens of samples across BigQuery, IAM, networks, MySQL, Google Kubernetes Engine (GKE) and more to work with.
Of course, we stored these configured Constraints in our version-controlled Policy Library.
- We looked at a simple set of Terraform code to define a GCS bucket, and stored the Terraform plan to a file before applying it.
- We ran Forseti’s Terraform Validator against the Terraform plan file, and had the Validator compare the plan to our Policy Library.
- We saw that the results matched our expectations! Compliance with the location specified in our Constraint passed the Validator’s checks, and non-compliance triggered a violation.
Awesome. And the best part is that all this required no special permissions, no infrastructure for servers or agents and no networking.
All of that comes with the full Forseti suite of Inventory taking Config Validation of already deployed resources. We might get to that next time.
References:
https://github.com/GoogleCloudPlatform/terraform-validator https://github.com/forseti-security/policy-library https://www.openpolicyagent.org/docs/latest/policy-language/ https://cloud.google.com/blog/products/identity-security/using-forseti-config-validator-with-terraform-validator https://forsetisecurity.org/docs/latest/concepts/