I have used the instructions here to configure Snowpipe for several projects.
Although it is accurate, it is entirely click-ops oriented. I like to automate (and script) everything, so I have created a fully automated implementation using PowerShell, the aws and snowsql CLIs.
The challenge is that you need to go back and forth between AWS and Snowflake, exchanging information from each platform with the other.
Overview
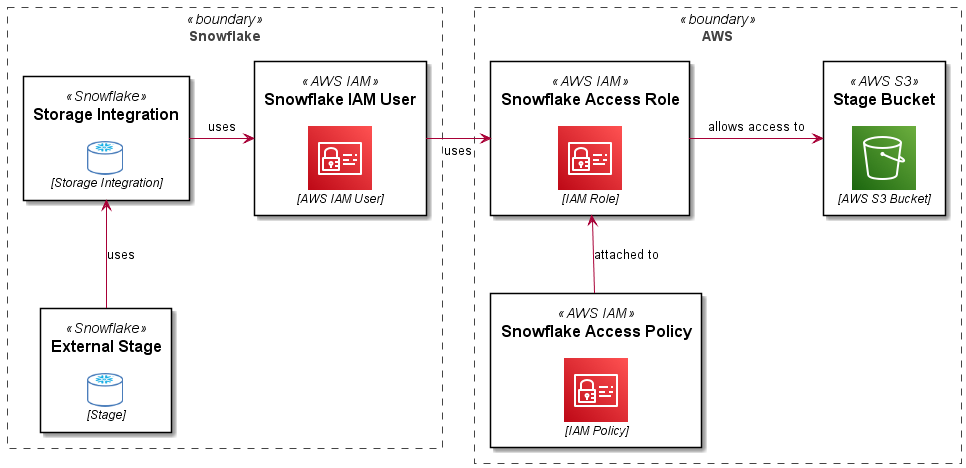
A Role Based Storage Integration in Snowflake allows a user (an AWS user arn) in your Snowflake account to use a role in your AWS account, which in turns enables access to S3 and KMS resources used by Snowflake for an external stage.
The following diagram explains this (along with the PlantUML code used to create the diagram..):
- Overview
- PlantUML
@startuml
skinparam rectangle<<boundary>> {
Shadowing false
StereotypeFontSize 0
FontColor #444444
BorderColor #444444
BorderStyle dashed
}
skinparam defaultTextAlignment center
!$imgroot = "https://github.com/avensolutions/plantuml-cloud-image-library/raw/main/images"
!unquoted procedure $AwsIam($alias, $label, $techn, $descr="", $stereo="AWS IAM")
rectangle "==$label\n\n<img:$imgroot/aws/SecurityIdentityCompliance/Iam.png>\n//<size:12>[$techn]</size>//" <<$stereo>> as $alias #white
!endprocedure
!unquoted procedure $AwsS3($alias, $label, $techn, $descr="", $stereo="AWS S3")
rectangle "==$label\n\n<img:$imgroot/aws/Storage/S3.png>\n//<size:12>[$techn]</size>//" <<$stereo>> as $alias #white
!endprocedure
!unquoted procedure $Snowflake($alias, $label, $techn, $descr="", $stereo="Snowflake")
rectangle "==$label\n\n<img:$imgroot/snowflake/snowflakeDB.png{scale=0.70}>\n//<size:12>[$techn]</size>//" <<$stereo>> as $alias #white
!endprocedure
rectangle "Snowflake" <<boundary>> {
$AwsIam(user, Snowflake IAM User, AWS IAM User)
$Snowflake(int, Storage Integration, Storage Integration)
$Snowflake(stage, External Stage, Stage)
}
rectangle "AWS" <<boundary>> {
$AwsS3(bucket, Stage Bucket, AWS S3 Bucket)
$AwsIam(role, Snowflake Access Role, IAM Role)
$AwsIam(policy, Snowflake Access Policy, IAM Policy)
}
stage -UP-> int : uses
int -RIGHT-> user : uses
user -RIGHT-> role : uses
policy -UP-> role : attached to
role -RIGHT-> bucket : allows access to
@enduml
Setup
Some prerequisites (removed for brevity):
- set the following variables in your script:
$accountid– your AWS account ID$bucketname– the bucket you are letting Snowflake use as an External Stage$bucketarn– used in policy statements (you could easily derive this from the bucket name)$kmskeyarn– assuming you are used customer managed encryption keys, your Snowflake storage integration will need to use these to decrypt data in the stage$prefix– if you want to set up granular access (on a key/path basis)
- Configure Snowflake access credentials using environment variables or using the
~/.snowsql/configfile (you should definitely use theSNOWSQL_PWDenv var for your password however) - Configure access to AWS using
aws configure
The actions performed in both AWS and Snowflake required privileged access on both platforms.
The Code
I have broken this into steps, the complete code is included at the end of the article.
Create Policy Documents
You will need to create the policy documents to allow the role you will create to access objects in the target S3 bucket, you will also need an initial “Assume Role” policy document which will be used to create the role and then updated with information you will get from Snowflake later.
Create Snowflake Access Policy
Use the snowflake_policy_doc.json policy document created in the previous step to create a managed policy, you will need the arn returned in a subsequent statement.
Create Snowflake IAM Role
Use the initial assume_role_policy_doc.json created to create a new Snowflake access role, you will need the arn for this resource when you configure the Storage Integration in Snowflake.
Attach S3 Access Policy to the Role
Now you will attach the snowflake-access-policy to the snowflake-access-role using the $policyarn captured from the policy creation statement.
Create Storage Integration in Snowflake
Use the snowsql CLI to create a Storage Integration in Snowflake supplying the $rolearn captured from the role creation statement.
Get STORAGE_AWS_IAM_USER_ARN and STORAGE_AWS_EXTERNAL_ID
You will need the STORAGE_AWS_IAM_USER_ARN and STORAGE_AWS_EXTERNAL_ID values for the storage integration you created in the previous statement, these will be used to updated the assume role policy in your snowflake-access-role.
Update Snowflake Access Policy
Using the STORAGE_AWS_IAM_USER_ARN and STORAGE_AWS_EXTERNAL_ID values retrieved in the previous statements, you will update the assume-role-policy for the snowflake-access-role.
Test the Storage Integration
To test the connectivity between your Snowflake account and your AWS external stage using the Storage Integartion just created, create a stage as shown here:
Now list objects in the stage (assuming there are any).
list @my_stage;
This should just work! You can use your storage integration to create different stages for different paths in your External Stage bucket and use both of these objects to create Snowpipes for automated ingestion. Enjoy!
Complete Code
The complete code for this example is shown here:
if you have enjoyed this post, please consider buying me a coffee ☕ to help me keep writing!