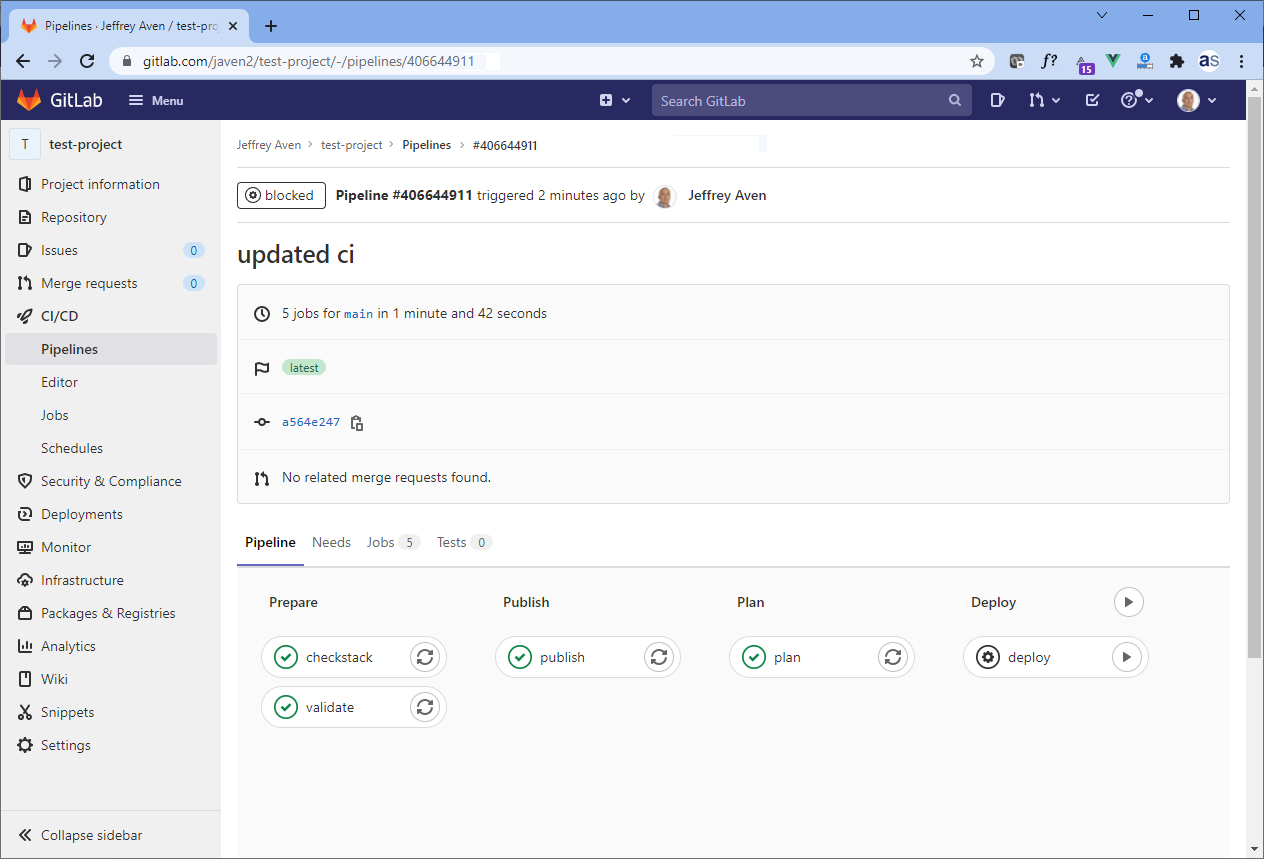
CloudFormation templates in large environments can grow beyond a manageable point. This article provides one approach to breaking up CloudFormation templates into modules which can be imported and used to create a larger template to deploy a complex AWS stack – using Jsonnet.
Jsonnet is a json pre-processing and templating library which includes features including user defined and built-in functions, objects, and inheritance amongst others. If you are not familiar with Jsonnet, here are some good resources to start with:
- Jsonnet
- Blog Article: Using Jsonnet to Configure Multiple Environments
- Blog Article: Using the Jsonnet Map Function
Advantages
Using Jsonnet you can use imports to break up large stacks into smaller files scoped for each resource. This approach makes CloudFormation template easier to read and write and allows you to apply the DRY (Do Not Repeat Yourself) coding principle (not possible with native CloudFormation templates.
Additionally, although as the template fragments are in Jsonnet format, you can add annotations or comments to your code similar to YAML (not possible with a JSON template alone), although the rendered template is in legal CloudFormation Json format.
Process Overview
The process is summarised here:
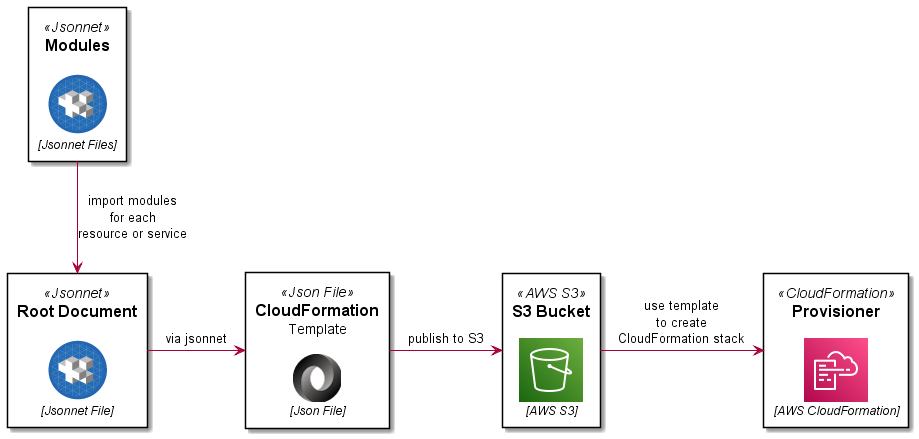
Code
This example will deploy a stack with a VPC and an S3 bucket with logging. The project directory structure would look like this:
templates/
├─ includes/
│ ├─ vpc.libsonnet
│ ├─ s3landingbucket.libsonnet
│ ├─ s3loggingbucket.libsonnet
│ ├─ tags.libsonnet
├─ template.jsonnet
Lets look at all of the constituent files:
template.jsonnet
This is the root document which will be processed by Jsonnet to render a legal CloudFormation JSON template. It will import the other files in the includes directory.
includes/tags.libsonnet
This code module is used to generate re-usable tags for other resources (DRY).
includes/vpc.libsonnet
This code module defines a VPC resource to be created with CloudFormation.
includes/s3loggingbucket.libsonnet
This code module defines an S3 bucket resource to be created in the stack which will be used for logging for other buckets.
includes/s3landingbucket.libsonnet
This code module defines an S3 landing bucket resource to be created in the stack.
Testing
To test the pre-processing, you will need a Jsonnet binary/executable for your environment. You can find Docker images which include this for you, or you could build it yourself.
Once you have a compiled binary, you can run the following to generate a rendered CloudFormation template.
jsonnet template.jsonnet -o template.json
You can validate this template using the AWS CLI as shown here:
aws cloudformation validate-template --template-body file://template.json
Deployment
In a previous article, Simplified AWS Deployments with CloudFormation and GitLab CI, I demonstrated an end-to-end deployment pipeline using GitLab CI. Jsonnet pre-processing can be added to this pipeline as an initial ‘preprocess’ stage and job. A snippet from the .gitlab-ci.yml file is included here:
Enjoy!
if you have enjoyed this post, please consider buying me a coffee ☕ to help me keep writing!