
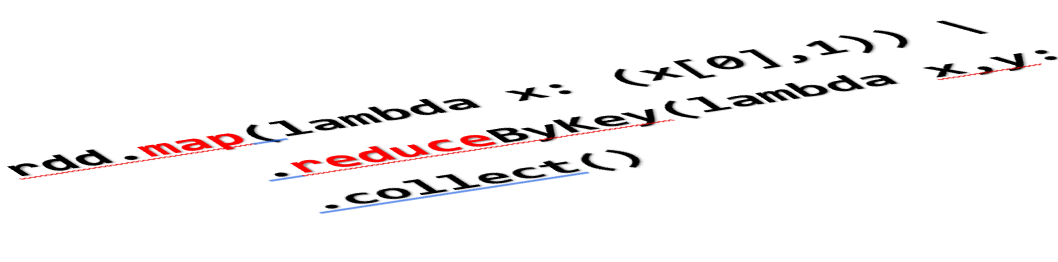
Firstly, this is not another Hadoop obituary, there are enough of those out there already.
The generalized title of this article has been used as an expression to convey the idea that something old has been replaced by something new. In the case of the expression “the King is dead, long live the King” the inference is that although one monarch has passed, another monarch instantly succeeds him.
In the age of instant gratification and hype cycle driven ‘pump and dump’ investment we are very quick to discard technologies that don’t realise overzealous targets for sales or market share. In our continuous attempts to find the next big thing, we are quick to throw out the last big thing and everything associated with it.
The Reports of My Death Have Been Greatly Exaggerated
A classic example of this is the notion that Map Reduce is dead. Largely proliferated by the Hadoop obituaries which seem to be growing exponentially with each day.
A common e-myth is that Google invented the Map Reduce pattern, which is completely incorrect. In 2004, Google described a framework distributed systems implementation of the Map Reduce pattern in a white paper named “MapReduce: Simplified Data Processing on Large Clusters.” – this would inspire the first-generation processing framework (MapReduce) in the Hadoop project. But neither Google nor Yahoo! nor contributors to the Hadoop project (which include the pure play vendors) created the Map Reduce algorithm or processing pattern and neither shall any one of these have the rights to kill it.
The origins of the Map Reduce pattern can be traced all the way back to the early foundations of functional programming beginning with Lambda Calculus in the 1930s to LISP in the 1960s. Map Reduce is an integral pattern in all of today’s functional and distributed systems programming. You only need to look at the support for map() and reduce() operators in some of the most popular languages today including Python, JavaScript, Scala, and many more languages that support functional programming.
As far as distributed processing frameworks go, the Map Reduce pattern and its map() and reduce() methods are very prominent as higher order functions in APIs such as Spark, Kafka Streams, Apache Samza and Apache Flink to name a few.
While the initial Hadoop adaptation of Map Reduce has been supplanted by superior approaches, the Map Reduce processing pattern is far from dead.
On the fall of Hadoop...
There is so much hysteria around the fall of Hadoop, we need to be careful not to toss the baby out with the bath water. Hadoop served a significant role in bringing open source, distributed systems from search engine providers to academia all the way to the mainstream, and still serves an important purpose in many organizations data ecosystems today and will continue to do so for some time.
OK, it wasn’t the panacea to everything, but who said it was supposed to be? The Hadoop movement was hijacked by hysteria, hype, venture capital, over ambitious sales targets and financial engineering – this does not mean the technology was bad.
Hadoop spawned many significant related projects such as Spark, Kafka and Presto to name a few. These projects paved the way for cloud integration, which is now the dominant vector for data storage, processing, and analysis.
While the quest for world domination by the Hadoop pure play vendors may be over, the Hadoop movement (and the impact it has had on the enterprise data landscape) will live on.
if you have enjoyed this post, please consider buying me a coffee ☕ to help me keep writing!