

Bigtable is one of the foundational services in the Google Cloud Platform and to this day one of the greatest contributions to the big data ecosystem at large. It is also one of the least known services available, with all the headlines and attention going to more widely used services such as BigQuery.
Background
In 2006 (pre Google Cloud Platform), Google released a white paper called “Bigtable: A Distributed Storage System for Structured Data”, this paper set out the reference architecture for what was to become Cloud Bigtable. This followed several other whitepapers including the GoogleFS and MapReduce whitepapers released in 2003 and 2004 which provided abstract reference architectures for the Google File System (now known as Colossus) and the MapReduce algorithm. These whitepapers inspired a generation of open source distributed processing systems including Hadoop. Google has long had a pattern of publicising a generalized overview of their approach to solving different storage and processing challenges at scale through white papers.

The Bigtable white paper inspired a wave of open source distributed key/value oriented NoSQL data stores including Apache HBase and Apache Cassandra.
What is Bigtable?
Bigtable is a distributed, petabyte scale NoSQL database. More specifically, Bigtable is…
a map
At its core Bigtable is a distributed map or an associative array indexed by a row key, with values in columns which are created only when they are referenced. Each value is an uninterpreted byte array.
sorted
Row keys are stored in lexographic order akin to a clustered index in a relational database.
sparse
A given row can have any number of columns, not all columns must have values and NULLs are not stored. There may also be gaps between keys.
multi-dimensional
All values are versioned with a timestamp (or configurable integer). Data is not updated in place, it is instead superseded with another version.
When (and when not) to use Bigtable
- You need to do many thousands of operations per second on TB+ scale data
- Your access patterns are well known and simple
- You need to support random write or random read operations (or sequential reads) - each using a row key as the primary identifier
Don’t use Bigtable if…
- You need explicit JOIN capability, that is joining one or more tables
- You need to do ad-hoc analytics
- Your access patterns are unknown or not well defined
Bigtable vs Relational Database Systems
The following table compares and contrasts Bigtable against relational databases (both transaction oriented and analytic oriented databases):
| Bigtable | RDBMS (OLTP) | RDBMS (DSS/MPP) | |
|---|---|---|---|
| Data Layout | Column Family Oriented | Row Oriented | Column Oriented |
| Transaction Support | Single Row Only | Yes | Depends (but usually no) |
| Query DSL | get/put/scan/delete | SQL | SQL |
| Indexes | Row Key Only | Yes | Yes (typically PI based) |
| Max Data Size | PB+ | '00s GB to TB | TB+ |
| Read/Write Throughput | "'000 | 000s queries/s" | '000s queries/s |
Bigtable Data Model
Tables in Bigtable are comprised of rows and columns (sounds familiar so far..). Every row is uniquely identified by a rowkey (like a primary key..again sounds familiar so far).
Columns belong to Column Families and only exist when inserted, NULLs are not stored - this is where it starts to differ from a traditional RDBMS. The following image demonstrates the data model for a fictitious table in Bigtable.

In the previous example, we created two Column Families (cf1 and cf2). These are created during table definition or update operations (akin to DDL operations in the relational world). In this case, we have chosen to store primary attributes, like name, etc in cf1 and features (or derived attributes) in cf2 like indicators.
Cell versioning
Each cell has a timestamp/version associated with it, multiple versions of a row can exist. Versions are naturally stored in descending order.
Properties such as the max age for a cell or the maximum number of versions to be stored for any given cell are set on the Column Family. Versions are compacted through a process called Garbage Collection - not to be confused with Java Garbage Collection (albeit same idea).
| Row Key | Column | Value | Timestamp |
|---|---|---|---|
| 123 | cf1:status | ACTIVE | 2020-06-30T08.58.27.560 |
| 123 | cf1:status | PENDING | 2020-06-28T06.20.18.330 |
| 123 | cf1:status | INACTIVE | 2020-06-27T07.59.20.460 |
Bigtable Instances, Clusters, Nodes and Tables
Bigtable is a "no-ops" service, meaning you do not need to configure machine types or details about the underlying infrastructure, save a few sizing or performance options - such as the number of nodes in a cluster or whether to use solid state hard drives (SSD) or the magnetic alternative (HDD). The following diagram shows the relationships and cardinality for Cloud Bigtable.
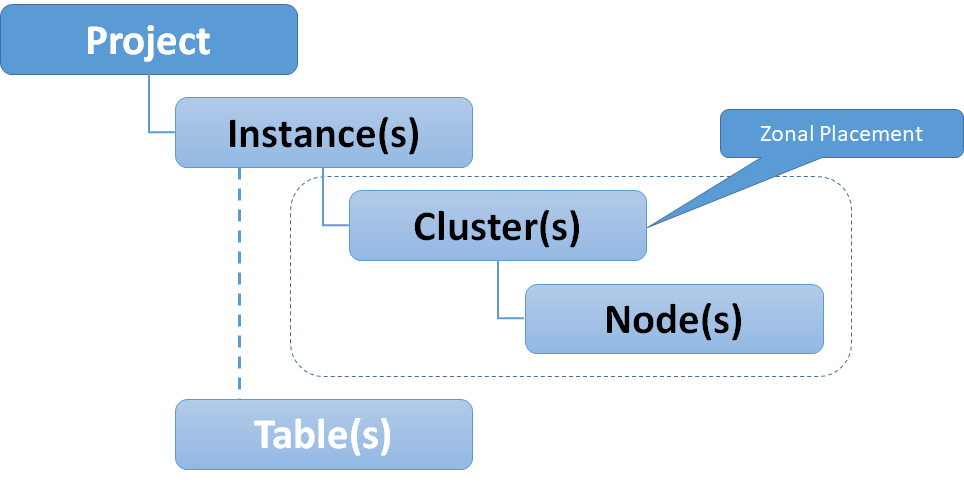
Clusters and nodes are the physical compute layer for Bigtable, these are zonal assets, zonal and regional availability can be achieved through replication which we will discuss later in this article.
Instances are a virtual abstraction for clusters, Tables belong to instances (not clusters). This is due to Bigtables underlying architecture which is based upon a separation of storage and compute as shown below.
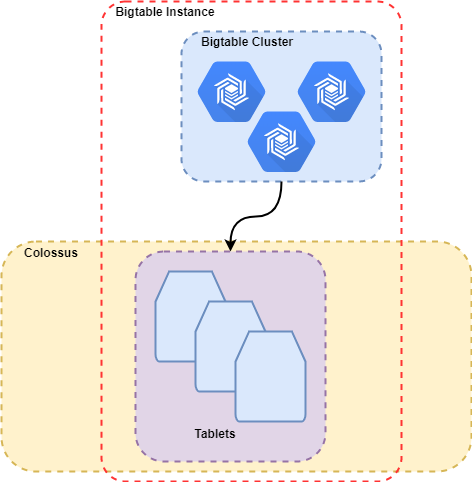
Bigtables separation of storage and compute allow it to scale horizontally, as nodes are stateless they can be increased to increase query performance. The underlying storage system in inherently scalable.
Physical Storage & Column Families
Data (Columns) for Bigtable is stored in Tablets (as shown in the previous diagram), which store "regions" of row keys for a particular Column Family. Columns consist of a column family prefix and qualifier, for instance:
cf1:col1
A table can have one or more Column Families. Column families must be declared at schema definition time (could be a create or alter operation). A cell is an intersection of a row key and a version of a column within a column family.
Storage settings (such as the compaction/garbage collection properties mentioned before) can be specified for each Column Family - which can differ from other column families in the same table.
Bigtable Availability and Replication
Replication is used to increase availability and durability for Cloud Bigtable – this can also be used to segregate read and write operations for the same table.
Data and changes to tables are replicated across multiple regions or multiple zones within the same region, this replication can be blocking (single row transactions) or non blocking (eventually consistent). However all clusters within a Bigtable instance are considered primary (writable).
Requests are routed using Application Profiles, a single-cluster routing policy can be used for manual failover, whereas a multi-cluster routing is used for automatic failover.
Backup and Export Options for Bigtable
Managed backups can be taken at a table level, new tables can be created from backups. The backups cannot be exported, however table level export and import operations are available via pre-baked Dataflow templates for data stored in GCS in the following formats:
- SequenceFiles
- Avro Files
- Parquet Files
- CSV Files
Accessing Bigtable
Bigtable data and admin functions are available via:
cbt(optional component of the Google SDK)hbase shell(REPL shell)- Happybase API (Python API for Hbase)
- SDK libraries for:
- Golang
- Python
- Java
- Node.js
- Ruby
- C#, C++, PHP, and more
As Bigtable is not a cheap service, there is a local emulator available which is great for application development. This is part of the Cloud SDK, and can be started using the following command:
gcloud beta emulators bigtable start
In the next article in this series we will demonstrate admin and data functions as well as the local emulator.
Next Up : Part II - Row Key Selection and Schema Design in Bigtable
if you have enjoyed this post, please consider buying me a coffee ☕ to help me keep writing!