
Kappa Architecture and Data Warehousing re-imagined
The aspiration to extend data analysis (predictive, descriptive or otherwise) to streaming event data has been common across every enterprise scale program I have been involved with. Often, however, this aspiration goes unrealised as it tends to slide down the priority scale as we still grapple with legacy batch oriented integration patterns and processes.
Event processing is not a new concept, real time event and transaction processing has been a standard feature for security, digital and operations functions for some time, however in the Data Warehousing, BI and Advanced Analytics worlds it is often spoken about but rarely implemented, except for tech companies of course. In many cases personalization is still a batch oriented process, e.g. train a model from a feature set built from historical data, generate recommendations in batch, serve these recommendations upon the next visit - wash, rinse, and repeat.
Lambda has existed for several years now as a data-processing architecture pattern designed to incorporate both batch and stream-processing capabilities. Moreover, messaging platforms have existed for decades, from point-to-point messaging systems, to message-oriented-middleware systems, to distributed pub-sub messaging systems such as Apache Kafka.
Additionally, open source streaming data processing frameworks and tools have proliferated in recent years with projects such as Storm, Samza, Flink and Spark Streaming becoming established solutions.
Kafka in particular, with its focus on durability, resiliency, availability and consistency, has graduated into fully fledged data platform not simply a transient messaging system. In many cases Kafka is serving as a back end for operational processes, such as applications implementing the CQRS (Command Query Responsibility Segregation) design pattern.
In other words, it is not the technology that holds us back, it's our lack of imagination.
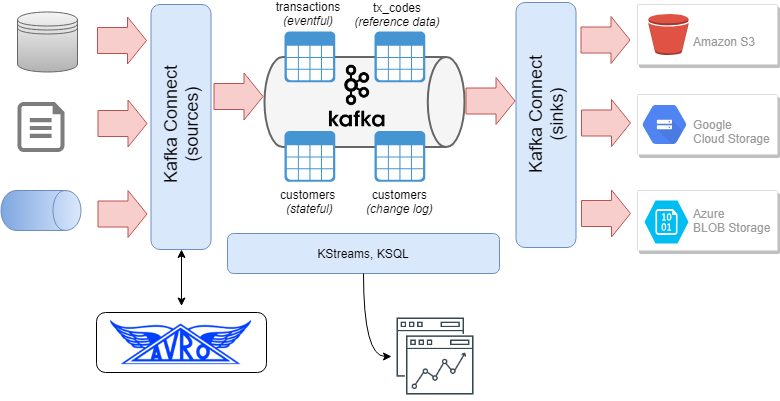
Enter Kappa Architecture where we no longer have to attempt to integrate streaming data with batch processes…everything is a stream. The ultimate embodiment of Kappa Architecture is the Streaming Data Warehouse.
In the Streaming Data Warehouse, tables are represented by topics. Topics represent either:
- unbounded event or change streams; or
- stateful representations of data (such as master, reference or summary data sets).
This approach makes possible the enrichment and/or summarisation of transaction or event data with master or reference data. Furthermore many of the patterns used in data warehousing and master data management are inherent in Kafka as you can represent the current state of an object as well as the complete change history of that object (in other words change data capture and associated slowly changing dimensions from one inbound stream).
Data is acquired from source systems either in real time or as a scheduled extract process, in either case the data is presented to Kafka as a stream.
The Kafka Avro Schema Registry provides a systematic contract with source systems which also serves as a data dictionary for consumers supporting schema evolution with backward and forward compatibility. Data is retained on the Kafka platform for a designated period of time (days or weeks) where it is available for applications and processes to consume - these processes can include data summarisation or sliding window operations for reporting or notification, or data integration or datamart building processes which sink data to other systems - these could include relational or non-relational data stores.
Real time applications can be built using the KStreams API and emerging tools such as KSQL can be used to provide a well-known interface for sampling streaming data or performing windowed processing operations on streams. Structured Streaming in Spark or Spark Streaming in its original RDD/DStream implementation can be used to prepare and enrich data for machine learning operations using Spark ML or Spark MLlib.
In addition, data sinks can operate concurrently to sink datasets to S3 or Google Cloud Storage or both (multi cloud - like real time analytics - is something which is talked about more than it’s implemented…).
In the Streaming Data Warehouse architecture Kafka is much more than a messaging platform it is a distributed data platform, which could easily replace major components of a legacy (or even a modern) data architecture.
It just takes a little imagination…
if you have enjoyed this post, please consider buying me a coffee ☕ to help me keep writing!