

This article provides an introduction to the Great Expectations Python library for data quality management (https://github.com/great-expectations/great_expectations).
So what are expectations when it comes to data (and data quality)...
An expectation is a falsifiable, verifiable statement about data. Expectations provide a language to talk about data characteristics and data quality - humans to humans, humans to machines and machines to machines.
The great expectations project includes predefined, codified expectations such as:
expect_column_to_exist
expect_table_row_count_to_be_between
expect_column_values_to_be_unique
expect_column_values_to_not_be_null
expect_column_values_to_be_between
expect_column_values_to_match_regex
expect_column_mean_to_be_between
expect_column_kl_divergence_to_be_less_than
… and many more
Expectations are both data tests and docs! Expectations can be presented in a machine-friendly JSON, for example:
Great Expectations provides validation results of defined expectations, which can dramatically shorten your development cycle.
[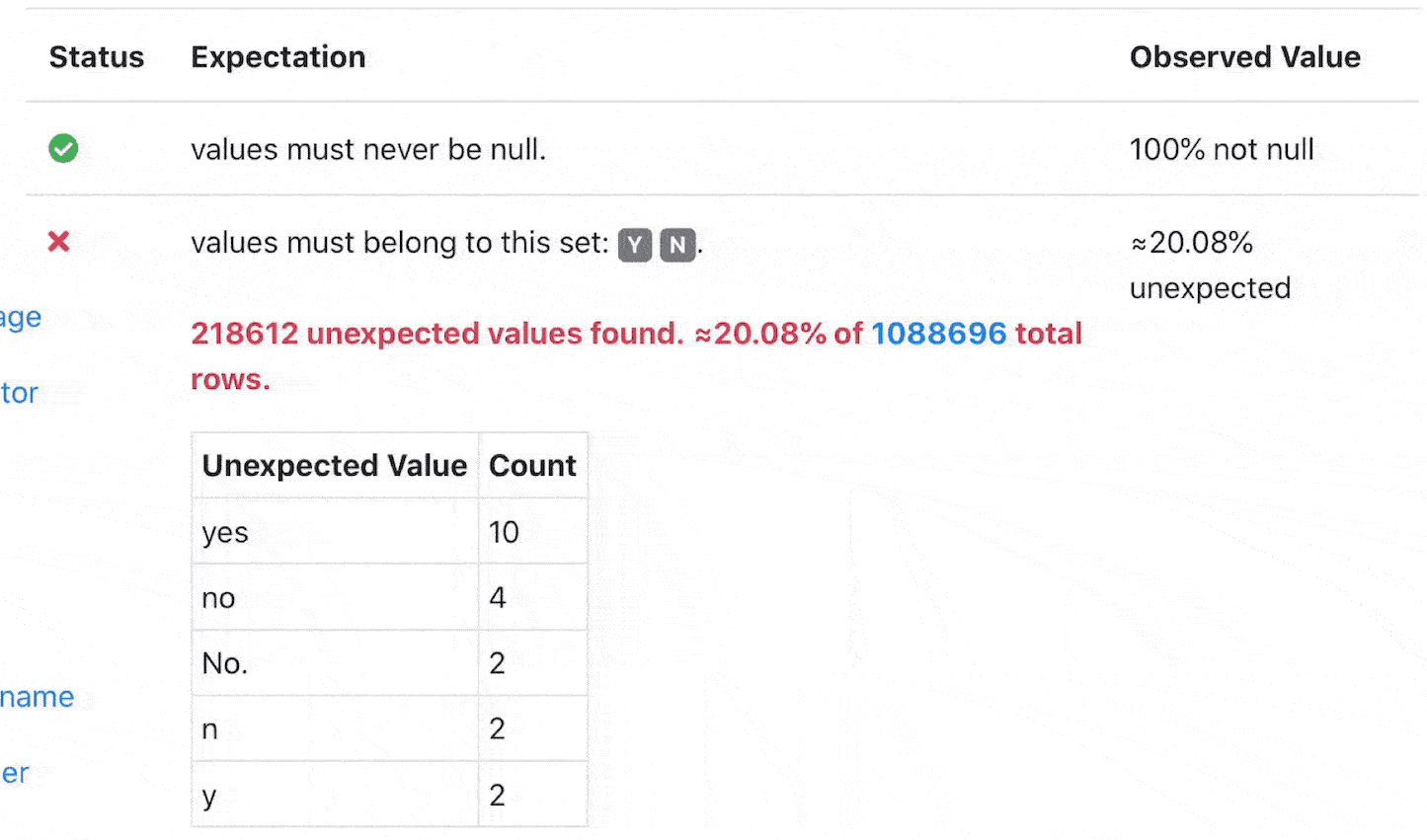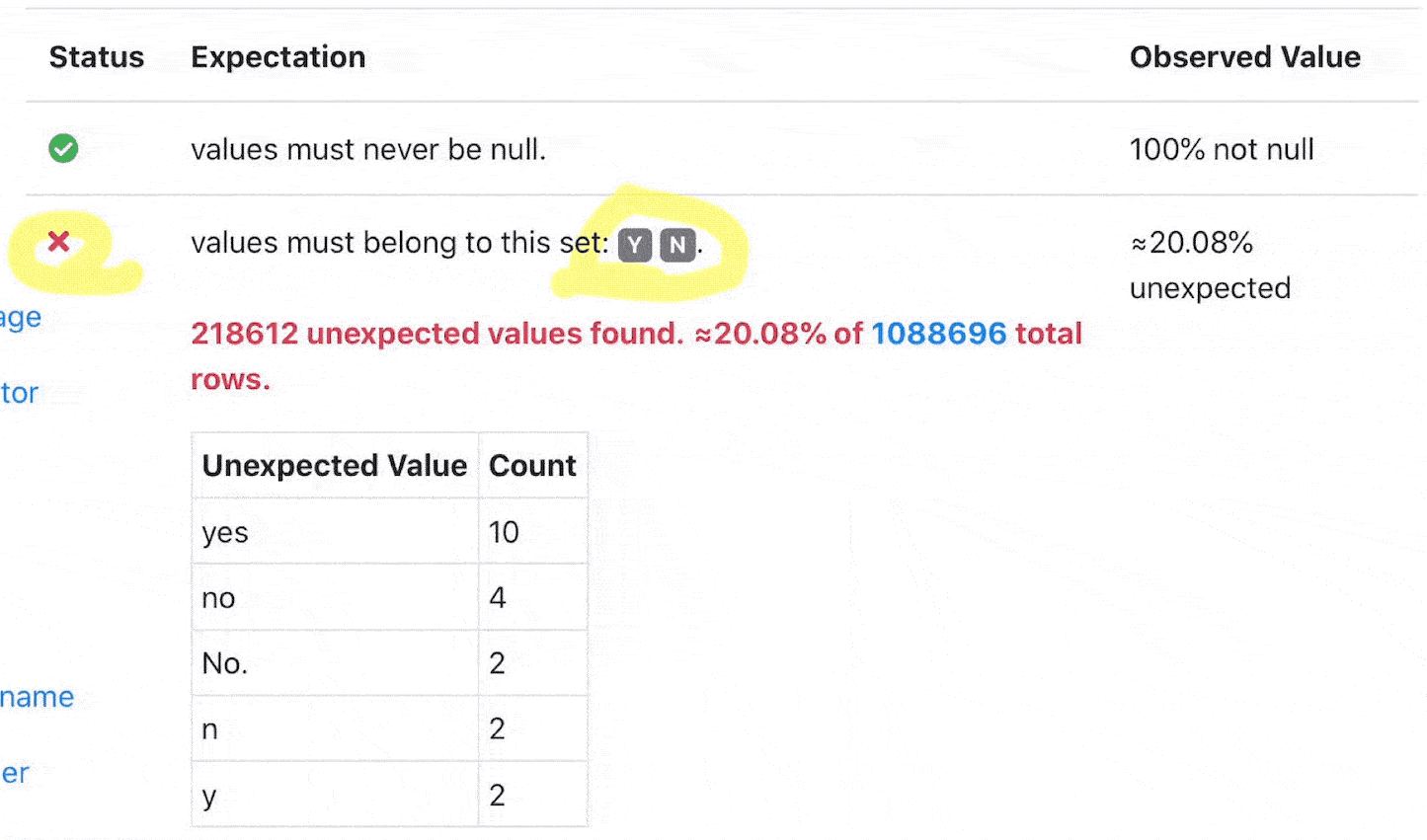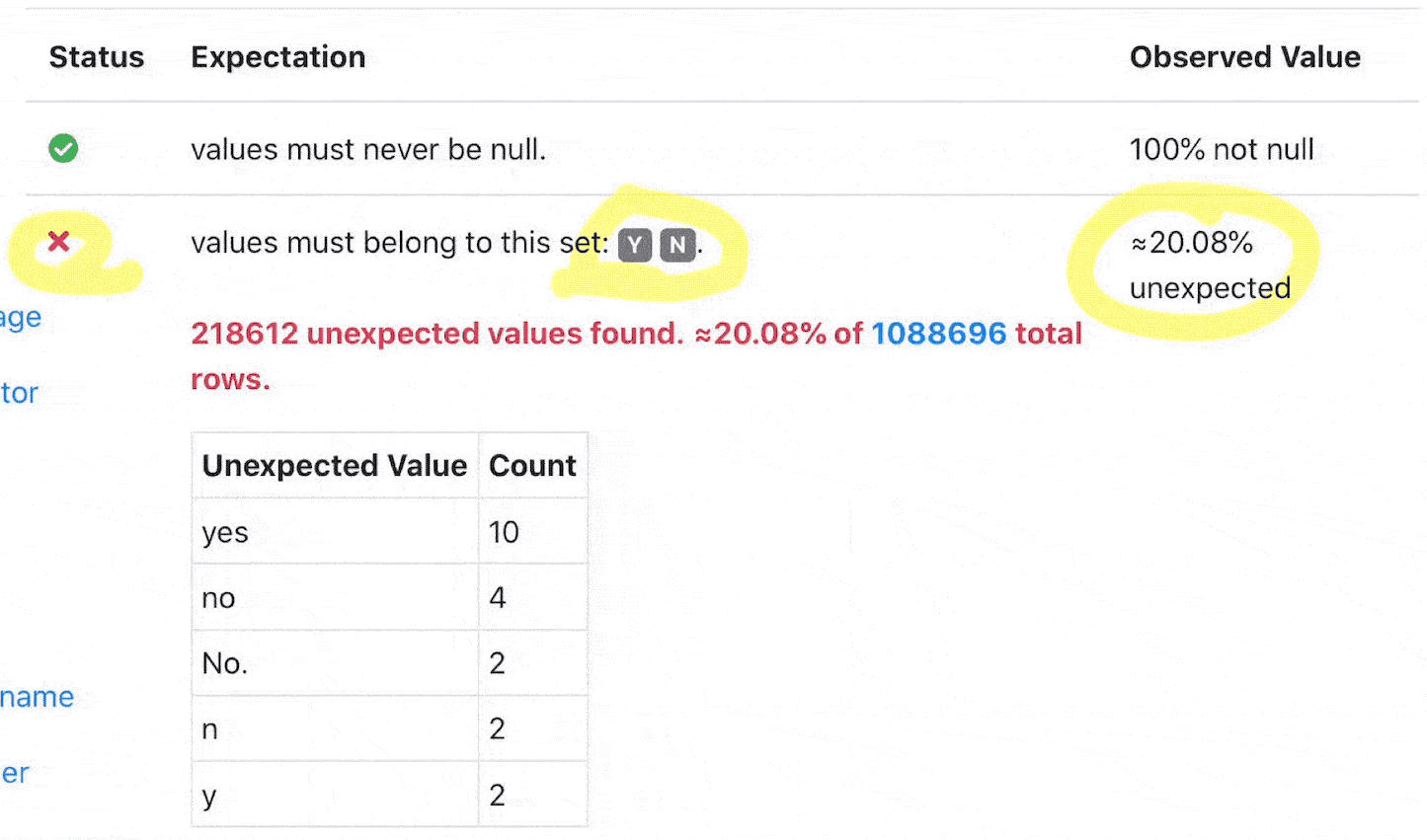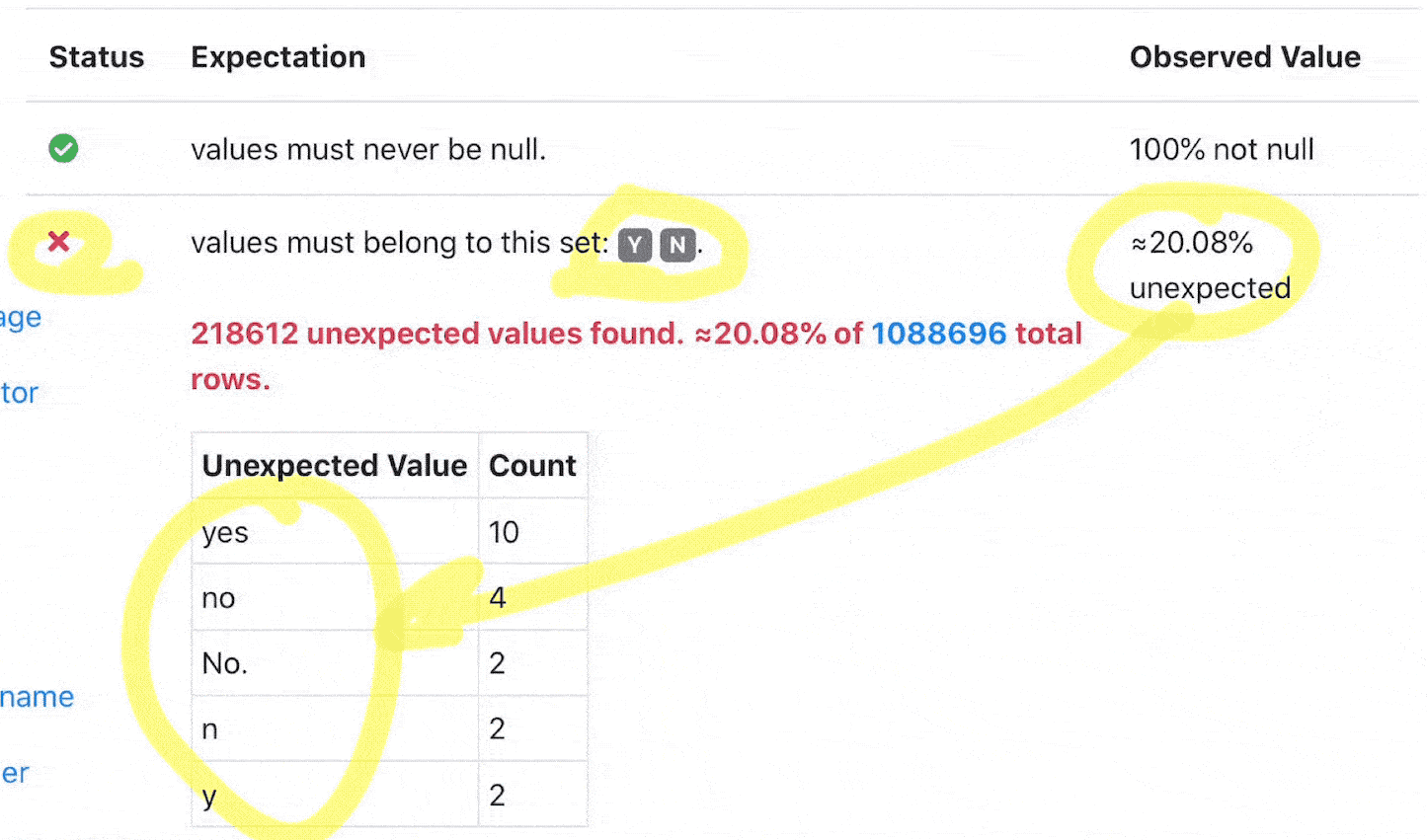 ](validation results in great expectations)
](validation results in great expectations)
Nearly 50 built in expectations allow you to express how you understand your data, and you can add custom expectations if you need a new one. A machine can test if a dataset conforms to the expectation.
OK, enough talk, let's go!
pyenv virtualenv 3.8.2 ge38
pip install great-expectations
tried with Python 3.7.2, but had issues with library lgzm on my local machine
once installed, run the following in the python repl shell:
showing the data in the dataframe should give you the following:
as can be seen, a collection of random integers in each column for our initial testing. Let's pipe this data in to great-expectations...
yields the following output...
this shows that there are 0 unexpected items in the data we are testing. Great!
Now let's have a look at a negative test. Since we've picked the values at random, there are bound to be duplicates. Let's test that:
yields...
The JSON schema has metadata information about the result, of note is the result section which is specific to our query, and shows the percentage that failed the expectation.
Let's progress to something more real-world, namely creating exceptions that are run on databases. Armed with our basic understanding of great-expectations, let's...
- set up a postgres database
- initiate a new Data Context within great-expectations
- write test-cases for the data
- group those test-cases and
- run it
Setting up a Database
if you don't have it installed,
wait 15 minutes for download the internet. Verify postgres running with docker ps, then connect with
Create some data
Take data for a spin
should yield
Now time for great-expectations
Great Expectations relies on the library sqlalchemy and psycopg2 to connect to your data.
once done, let's set up great-expectations
should look like below:
let's set up a few other goodies while we're here
Congratulations! Great Expectations is now set up
You should see a file structure as follows:
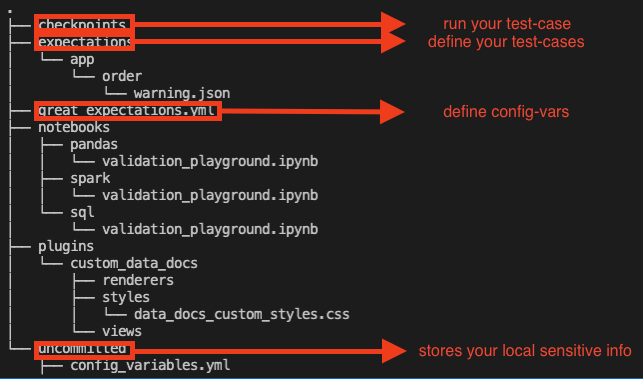
If you didn't generate a suite during the set up based on app.order, you can do so now with
great_expectations suite new
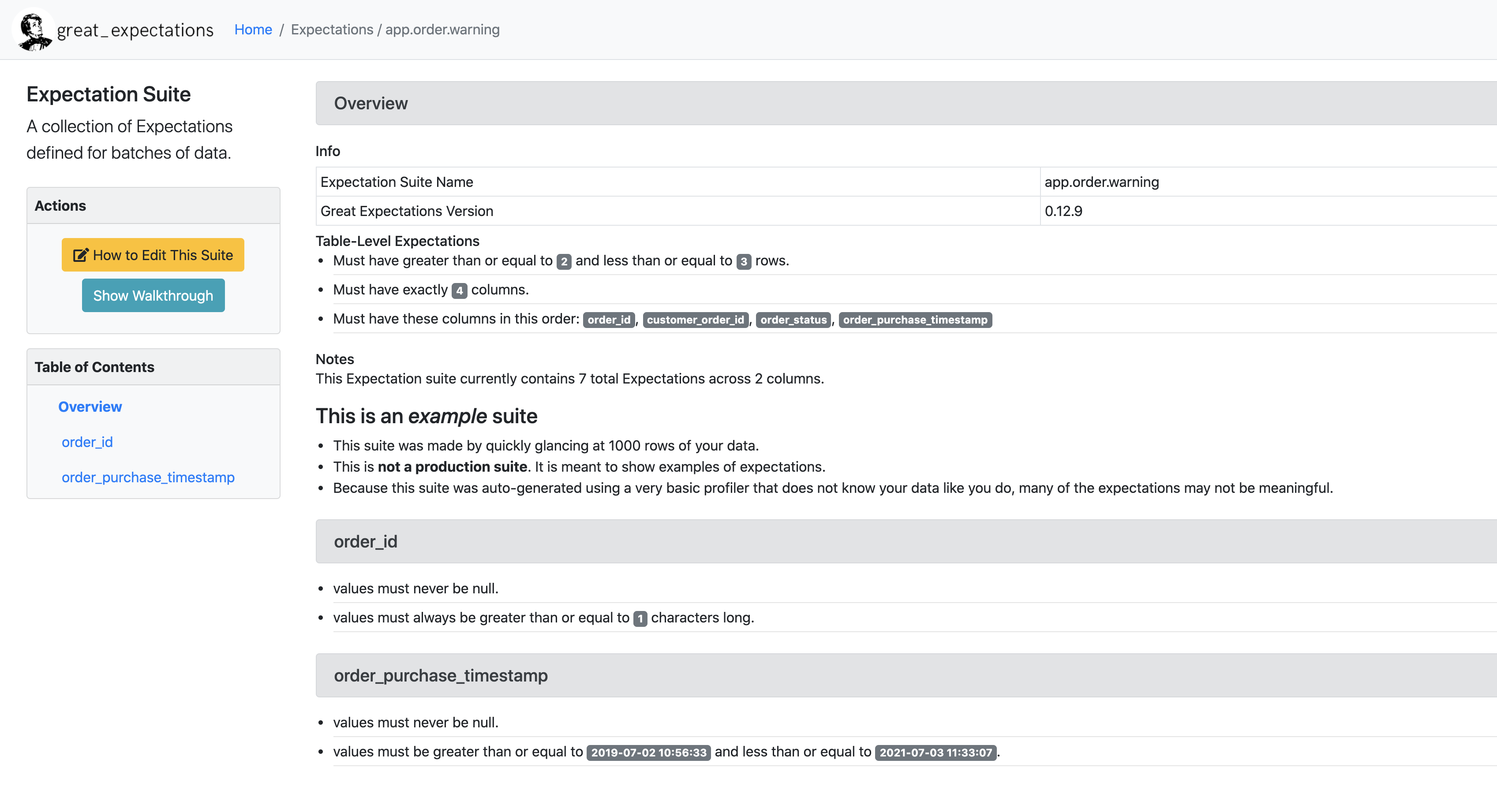
when created, looking at great_expectations/expectations/app/order/warning.json should yield the following:
as noted in the content section, this expectation config is created by the tool by looking at 1000 rows of the data. We also have access to the data-doc site which we can open in the browser at great_expectations/uncommitted/data_docs/local_site/index.html
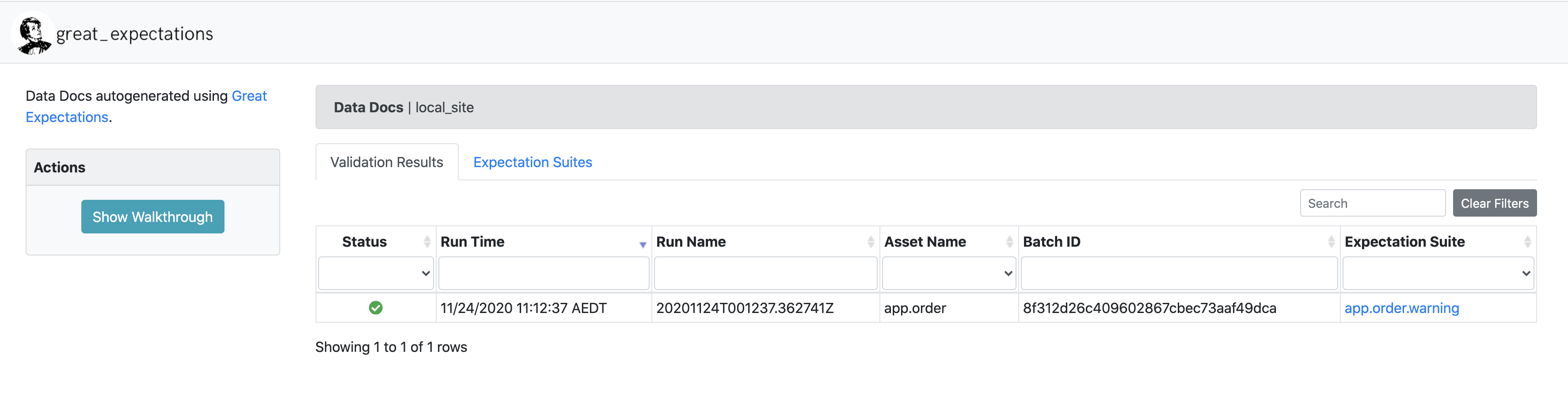
Clicking on app.order.warning, you'll see the sample expectation shown in the UI
Now, let's create our own expectation file and take it for a spin. We'll call this one error.
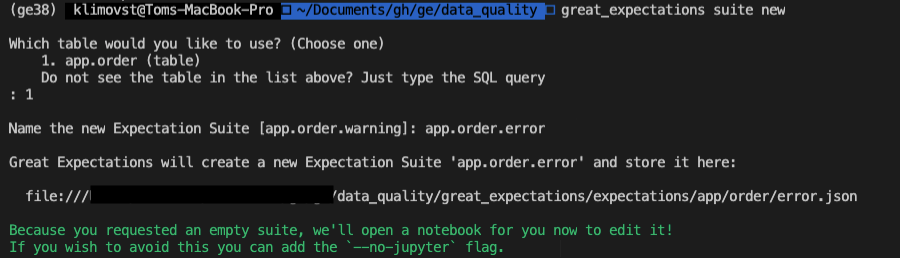
This should also start a jupyter notebook. If for some reason you need to start it back up again, you can do so with
Go ahead and hit run on your first cell.
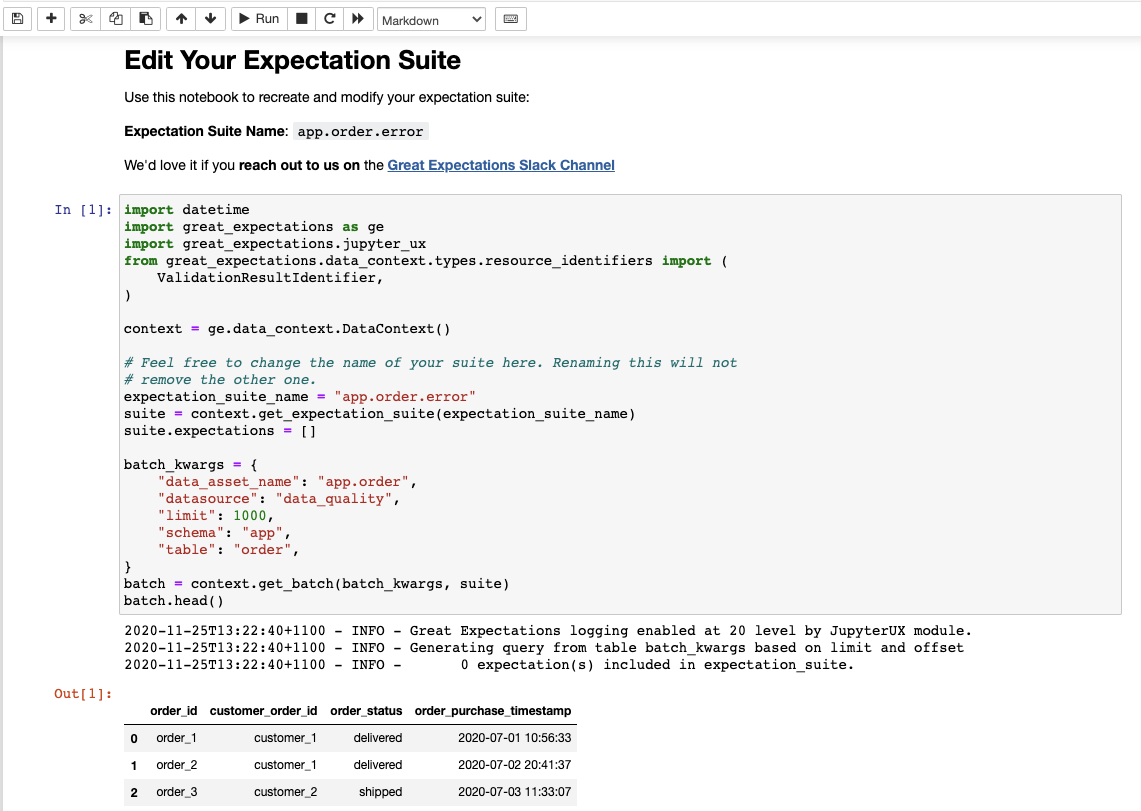
Let's keep it simple and test the customer_order_id column is in a set with the values below:
using the following expectations function in your Table Expectation(s). You may need to click the + sign in the toolbar to insert a new cell, as below:
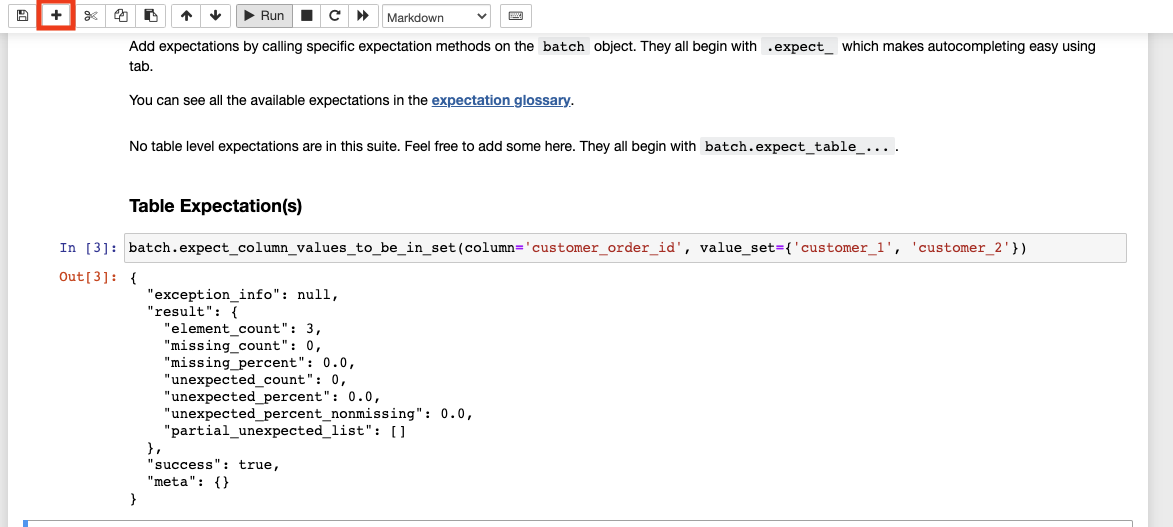
As we can see, appropriate json output that describes the output of our expectation. Go ahead and run the final cell, which will save our work and open a newly minted data documentation UI page, where you'll see the expectations you defined in human readable form.

Running the test cases
In Great Expectations, running a set of expectations (test cases) is called a checkpoint. Let's create a new checkpoint called first_checkpoint for our app.order.error expectation as shown below:
Let's take a look at our checkpoint definition.
Above you can see the validation_operator_name which points to a definition in great_expectations.yml, and the batches where we defined the data source and what expectations to run against.
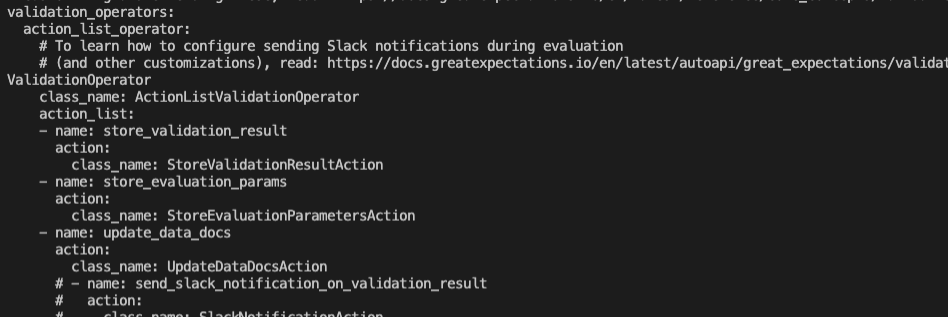
Let's have a look at great_expectations.yml. We can see the action_list_operator defined and all the actions it contains:
Let's run our checkpoint using

Okay cool, we've set up an expectation, a checkpoint and shown a successful status! But what does a failure look like? We can introduce a failure by logging in to postgres and inserting a customer_11 that we'll know will fail, as we've specific our expectation that customer_id should only have two values..
Here are the commands to make that happen, as well as the command to re-run our checkpoint:
Run checkpoint again, this time it should fail

As expected, it failed.
Supported Databases
In it's current implementation version 0.12.9, the supported databases our of the box are:
It's great to be BigQuery supported out of the box, but what about Google Spanner and Google BigTable? Short-answer; currently not supported. See tickets https://github.com/googleapis/google-cloud-python/issues/3022.
With respect to BigTable, it may not be possible as SQLAlchemy can only manage SQL-based RDBSM-type systems, while BigTable (and HBase) are NoSQL non-relational systems.
Scheduling
Now that we have seen how to run tests on our data, we can run our checkpoints from bash or a python script(generated using great_expectations checkpoint script first_checkpoint). This lends itself to easy integration with scheduling tools like airflow, cron, prefect, etc.
Production deployment
When deploying in production, you can store any sensitive information(credentials, validation results, etc) which are part of the uncommitted folder in cloud storage systems or databases or data stores depending on your infratructure setup. Great Expectations has a lot of options
When not to use a data quality framework
This tool is great and provides a lot of advanced data quality validation functions, but it adds another layer of complexity to your infrastructure that you will have to maintain and trouble shoot in case of errors. It would be wise to use it only when needed.
In general
Do not use a data quality framework, if simple SQL based tests at post load time works for your use case. Do not use a data quality framework, if you only have a few (usually < 5) simple data pipelines.
Do use it when you have data that needs to be tested in an automated and a repeatable fashion. As shown in this article, Great Expectations has a number of options that can be toggled to suit your particular use-case.
Conclusion
Great Expectations shows a lot of promise, and it's an active project so expect to see features roll out frequently. It's been quite easy to use, but I'd like to see all it's features work in a locked-down enterprise environment.
Tom Klimovski
Principal Consultant, Gamma Data
tom.klimovski@gammadata.io